在这个快节奏的数字化转型世界中,IT运营工程师面临的挑战之一是能够与组织内的创新保持相关性。负责保持正常运转很重要,但作为企业组织数字化转型加速的一部分也同样重要。
IT运营团队有时可能会被抛在后面,因为他们手头上的现有项目和日常消防工作非常紧张。重要的是,他们拥有的工具不仅可以帮助他们主动识别和解决问题,而且如果确实发生了,还能够快速解决这些问题。
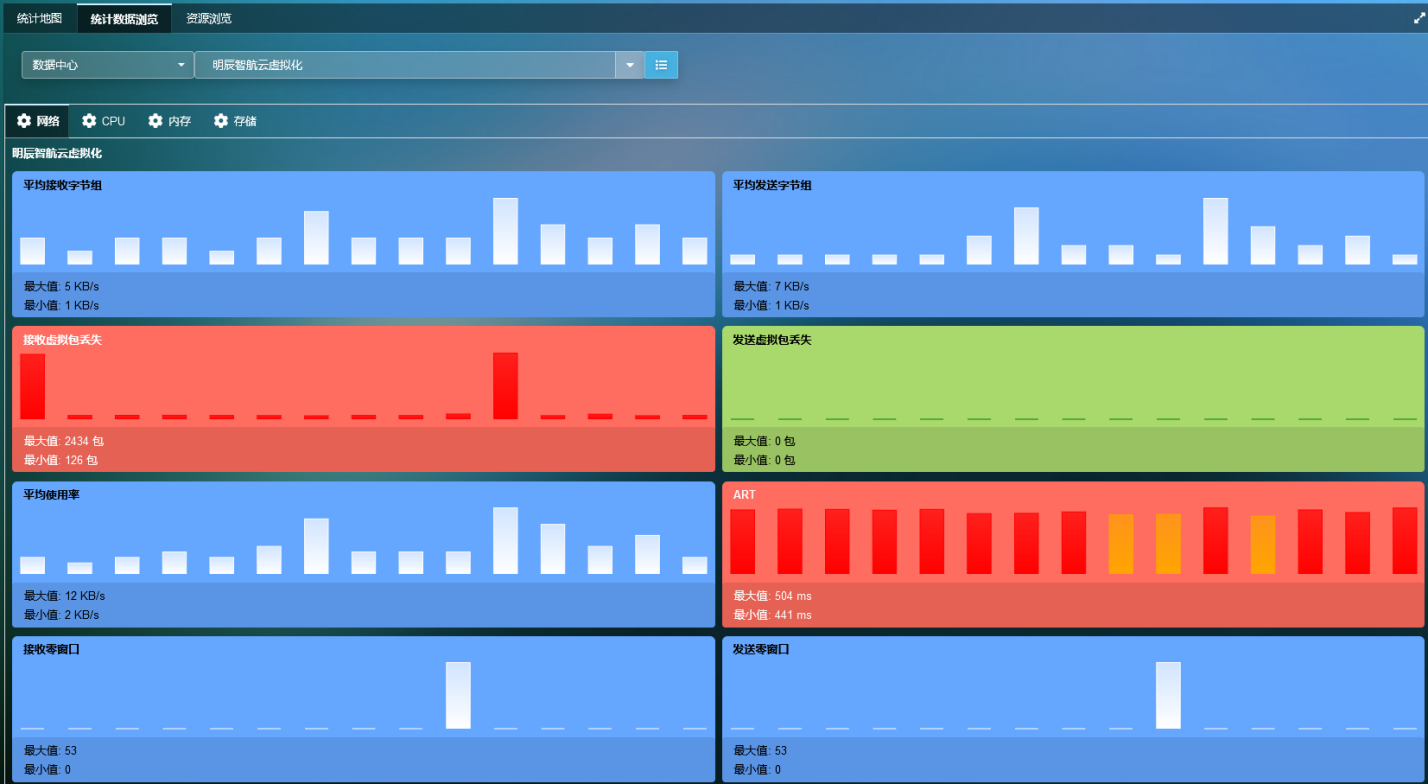
· 通过测量CPU交换等待、CPU就绪、利用率等指标,并将其与应用程序响应时间联系起来,可视化计算性能如何影响应用程序性能。
· 相对于当前在数据中心运行的基础架构,可视化主机中所有内存阵列的性能。 获取有关内存使用情况、交换率、交换等待时间等的最新信息。
· 对使用计算资源的进程的详细洞察。
· 解决资源配置不足和过度配置问题的指南。
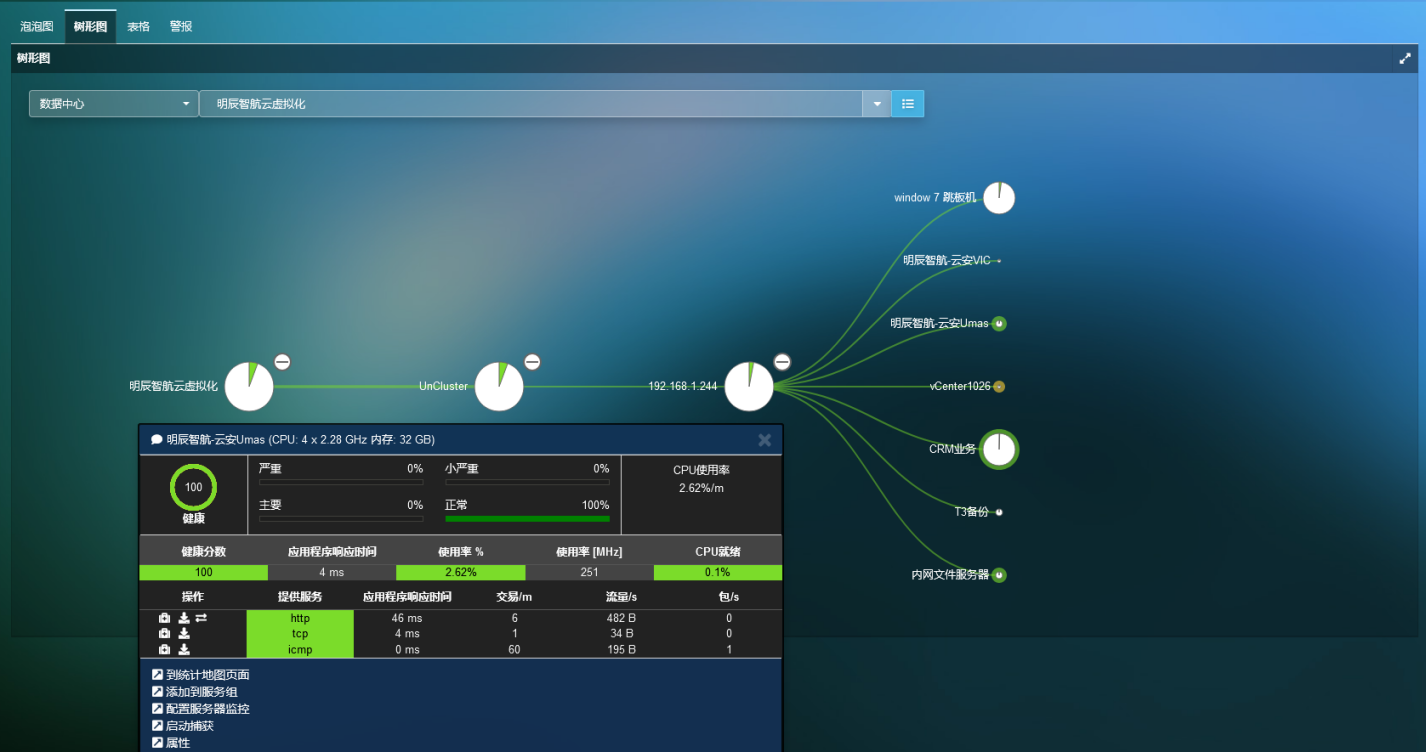
· 可视化vAPP网络流量如何穿越物理设备、虚拟实体和应用程序服务,以查明影响应用程序性能的网络节点。
· 查看每个应用程序的网络往返时间、流量、重试、数据包丢失、应用程序响应时间。
从应用程序或业务服务到其相关基础设施和网络根本原因的自上而下的可视化方法,以更快地解决根本原因。
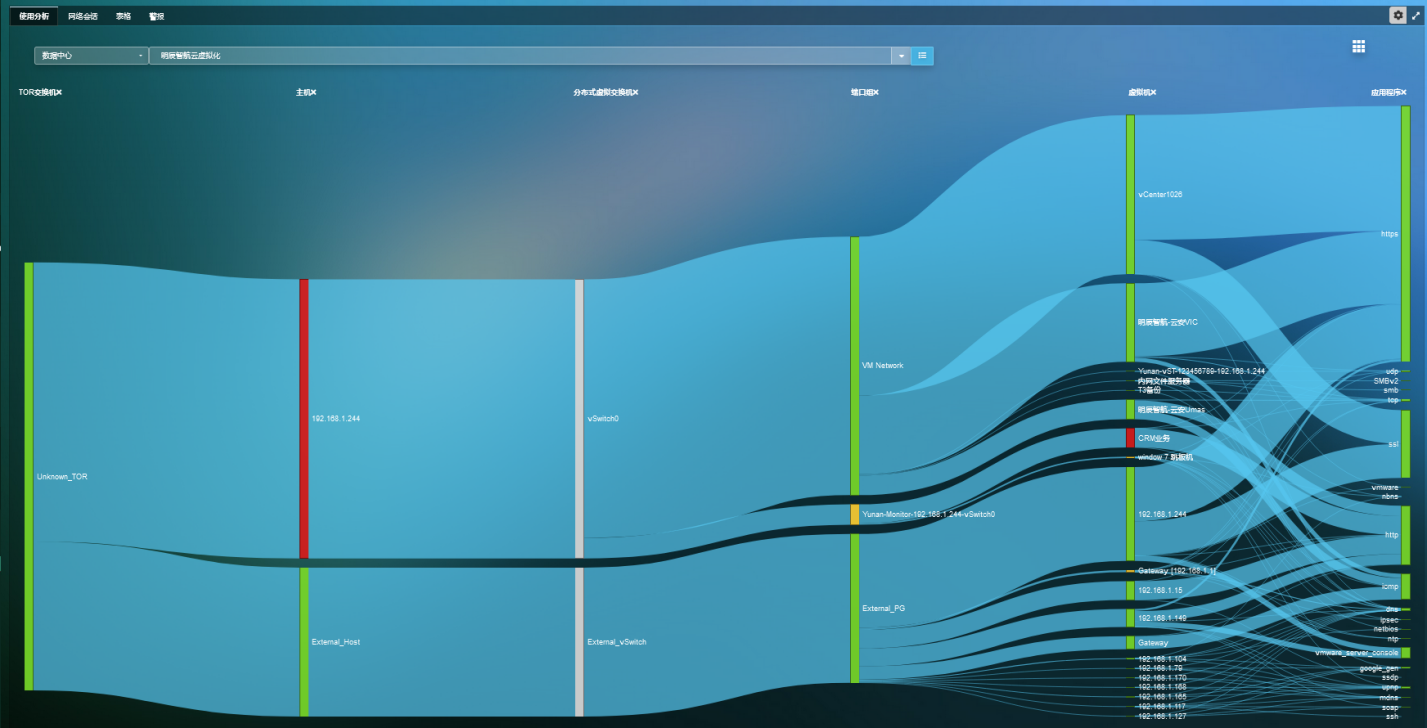
· 24 x 7 全天候监控多个供应商的存储阵列的存储性能。
· 通过深入了解存储节点来简化容量规划程序。
· 可视化有关跨 VM、虚拟磁盘和数据存储的读/写延迟和 IOPS 的趋势性能问题。
· 了解存储基础架构中存在问题的层并隔离所有性能问题。
· 可视化整个存储基础架构如何映射到应用程序,尤其是多层应用程序。
· 确定存在存储性能问题时哪些应用程序受到影响。
· 执行快速根本原因分析并将MTTR从几天缩短到几分钟。花时间解决问题,而不是发现问题。让云安为您做这件事。
· 利用连续机器学习 (ML) 和行为学习算法从性能基线而不是猜测中识别异常,以提供前所未有的准确度。
· 仅在重要问题上获得警报,从而防止警报风暴和误报。
· 无需手动解释来自多个来源的问题。 让云安为您做这件事。
· 实时或过去的时间以检测和解决间歇性问题。
IT运营工程师通常首先因任何投诉而受到指责,无论是否与基础架构相关。
IT运营工程师通常没有解决问题的正确工具,或者拥有难以使用的工具,他们总是被动地应对突发事件和灭火。 例如,他们不断与其他团队就问题的真正根本原因进行指责。
这导致他们不仅落后于创新项目,而且落后于现有基础设施的简单实施和升级。
对于这些工程师来说,在差距成为问题之前找出差距很重要。 在几秒钟内找到根本原因(甚至在领导问之前告诉领导!), 是时候让他们收回对虚拟环境的控制权,并通过了解错误并修复它来成为英雄。

微信公众号

新浪微博







