现场如下图所示:

开始排查网络问题
在监控里面发现网络一直很稳定。而且如果是网络出现问题,同一网段的应用应该也都会报错才对。事实上只有对应的应用和中间件报错。
排查日志
发现一旦有 中间件的register err 必定会出现中间件调用后端数据库的sql read timeout的报错。但这两个报错完全不是在一个线程里面的,一个是处理前端的Reactor线程,一个是处理后端SQL的Worker线程,如下图所示:
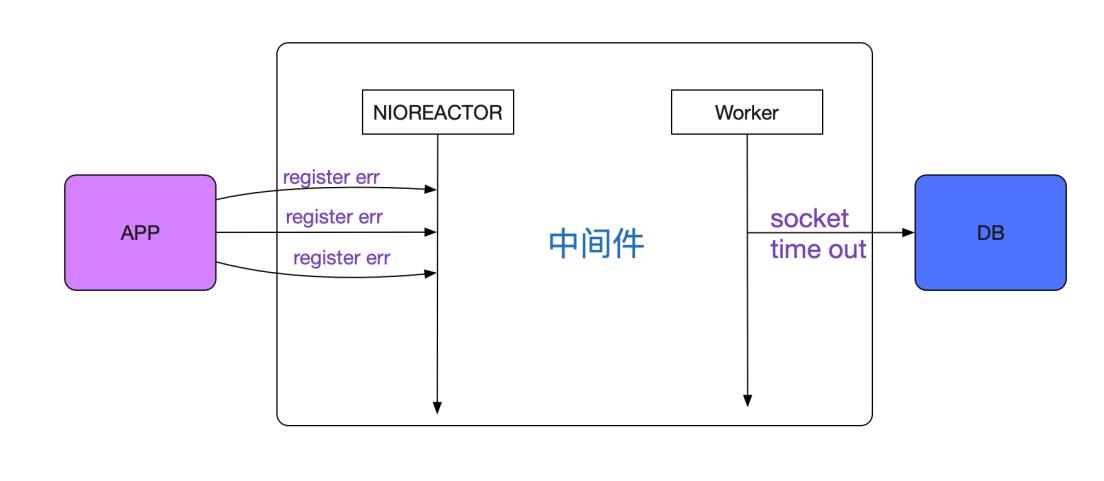
这两个线程是互相独立的,代码中并没有发现任何机制能让这两个线程互相影响。
进一步进行排查
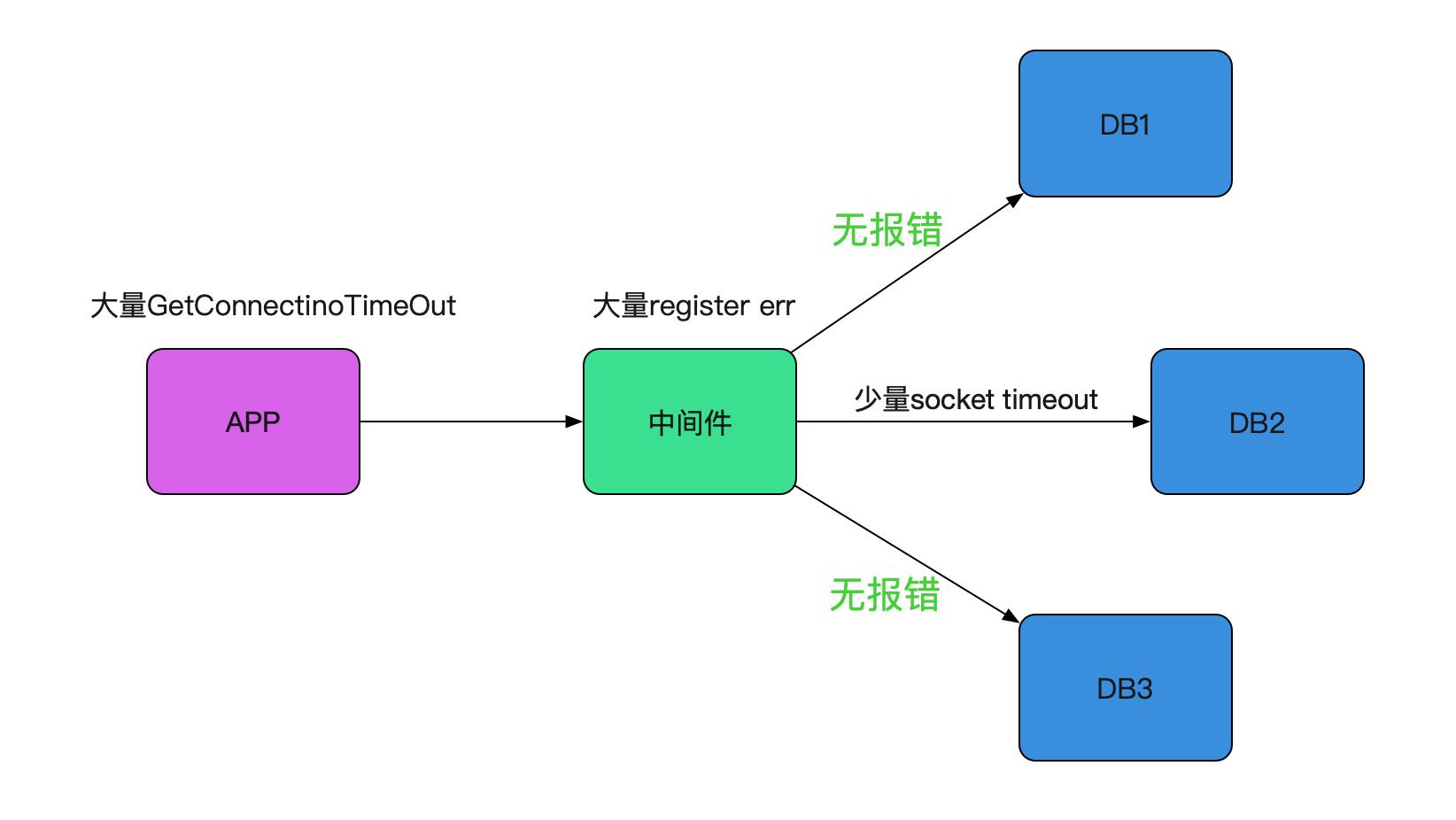
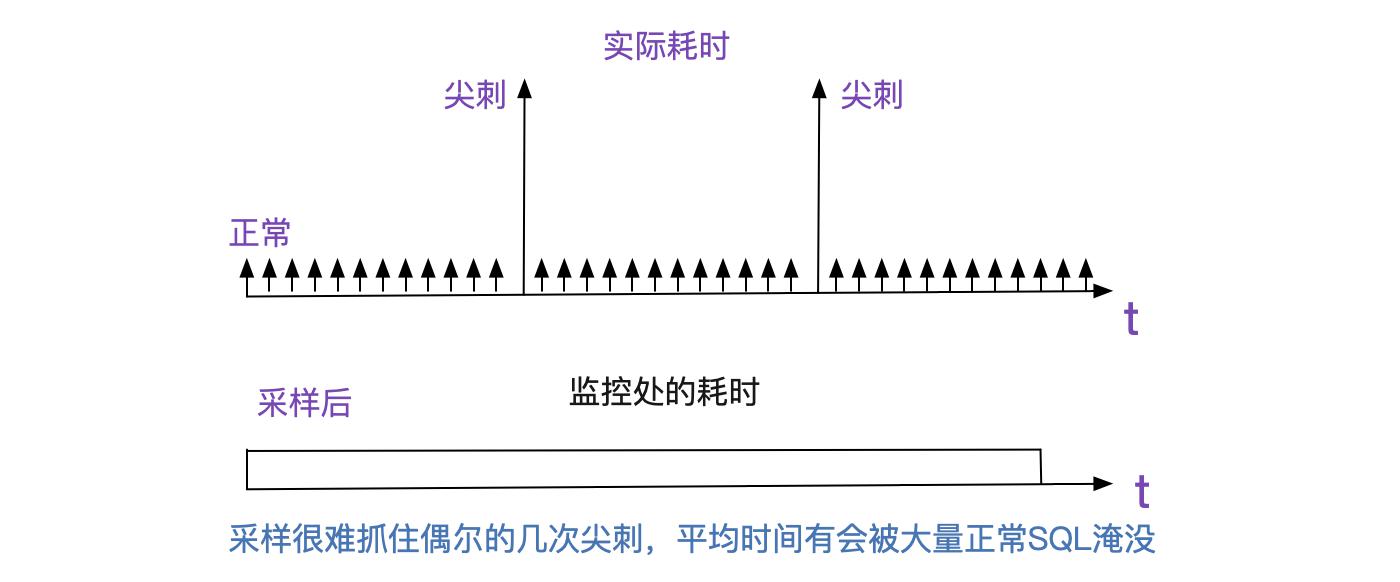
和之前的慢SQL一样,都是调用第二个数据库超时,而DBA那边却说SQL执行没有任何异常,
感觉明显SQL执行有问题,只不过DBA是采样而且将采样耗时平均的,偶尔的几笔耗时并不会在整体SQL的耗时里面有所体现。
日志分析
从日志入手, REACTOR线程和Worker线程同时报错,但两者并无特殊的关联,说明可能是同一个原因引起的两种不同现象。在线上报错日志里面进行细细搜索,发现在大量的
NIOReactor-1-RW register err java.nio.channels.CloasedChannelException
日志中会掺杂着这个报错:
NIOReactor-1-RW Socket Read timed out
at XXXXXX . doCommit
at XXXXXX Socket read timedout
发现了端倪,Reactor作为一个IO线程,我们的中间件在处理commit/rollback这样的操作时候还是在Reactor线程进行的。很明显Reactor线程卡主是由于commit慢了
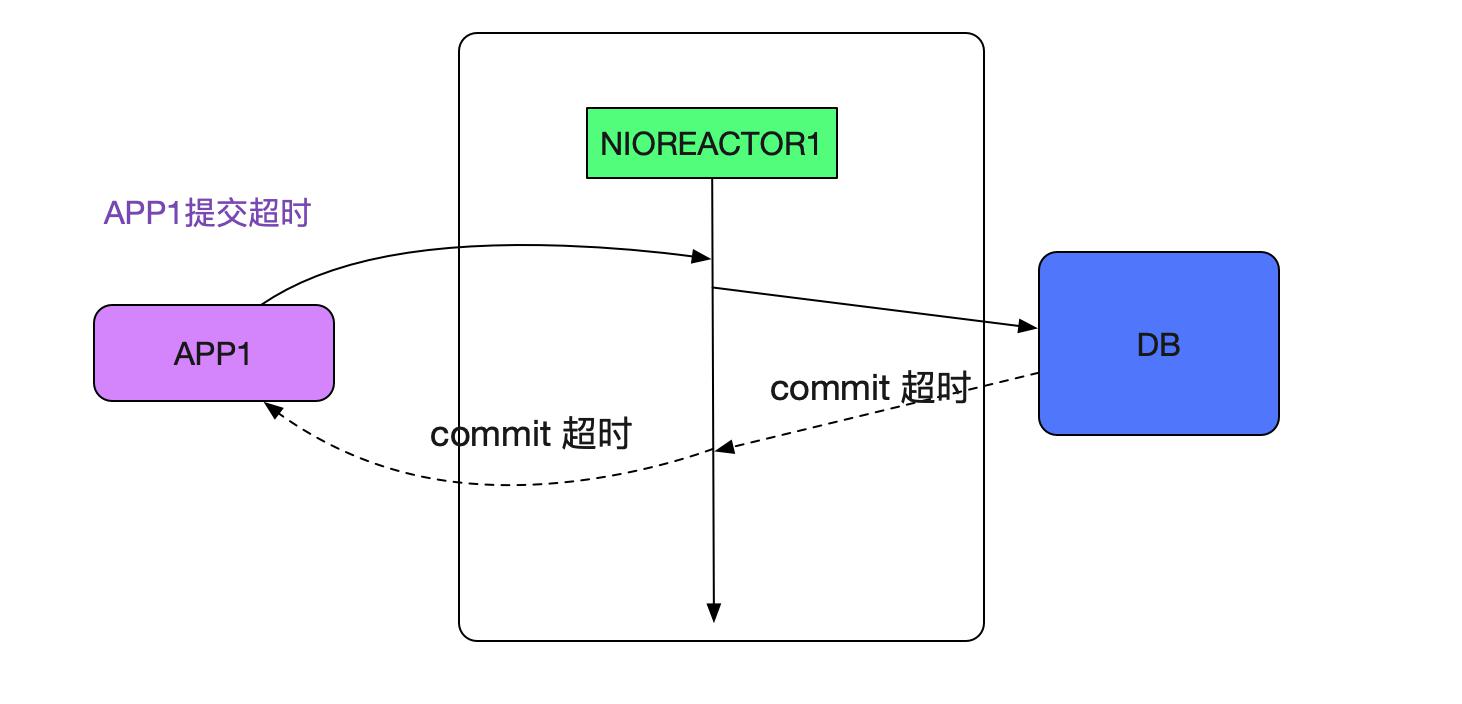
由于app1的commit特别慢而卡住了reactor1线程,从而落在reactor1线程上的握手操作都会超时!如下图所示:
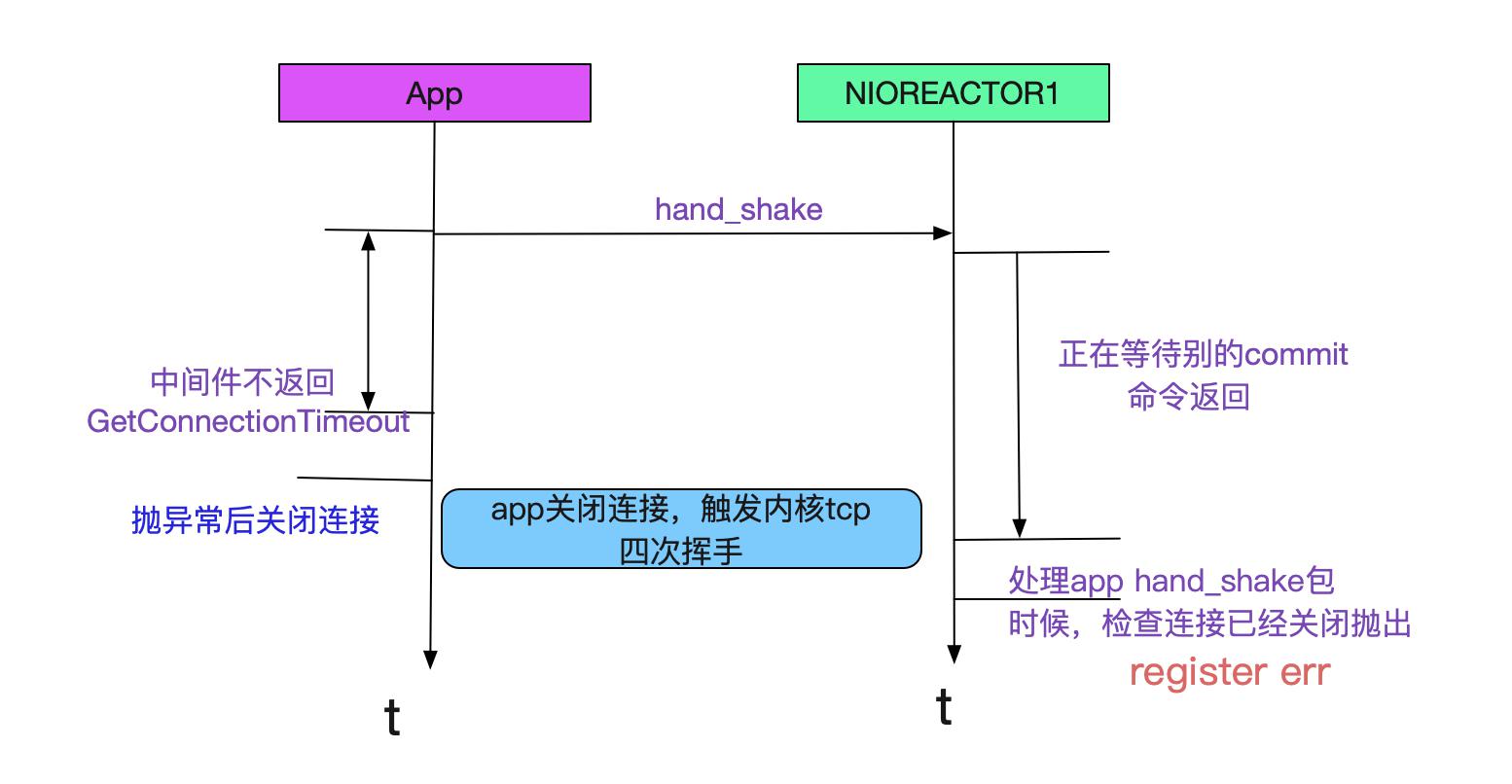
为什么commit会变慢?
commit变慢所关联的DB正好也是出现慢SQL的那个DB。发现其中和存储相关的HBA卡有报错!如下图所示:
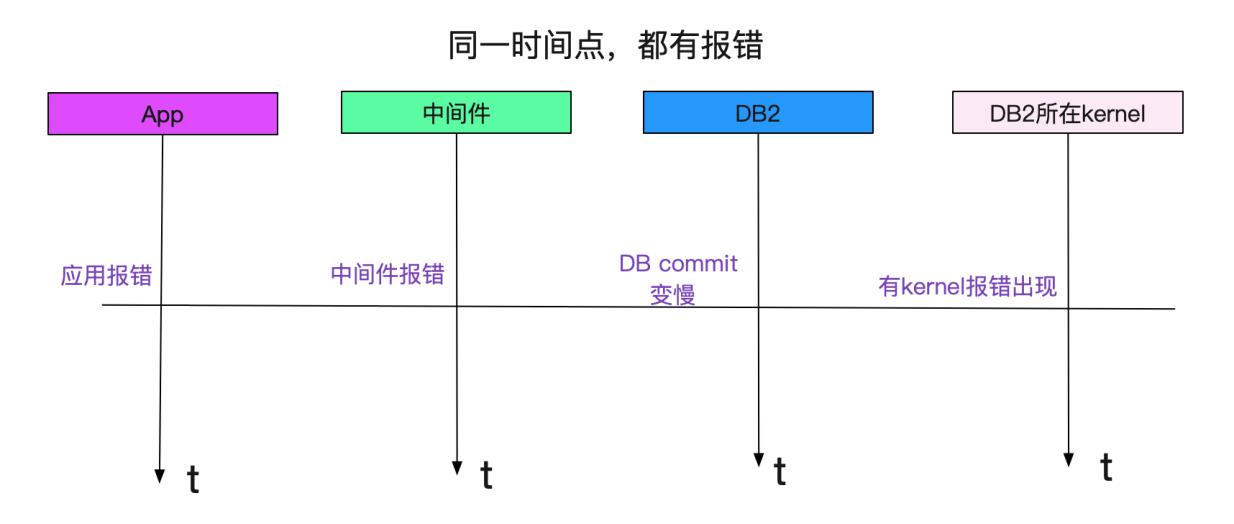
报错时间都是一致的!

微信公众号

新浪微博







