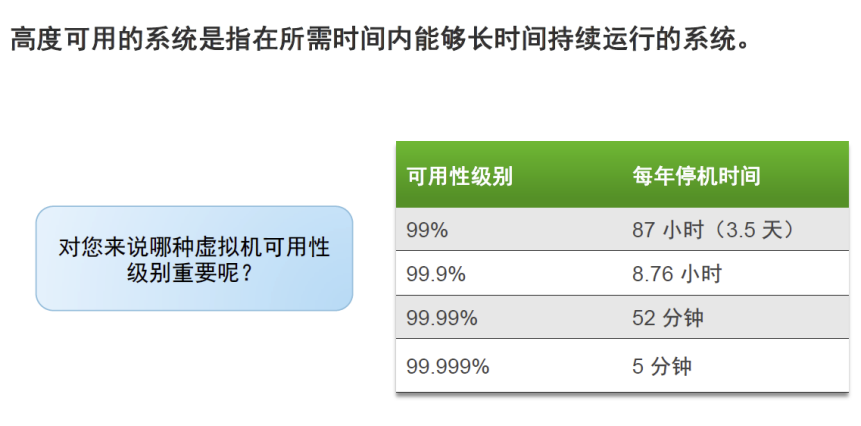
●不同级别的高可用:
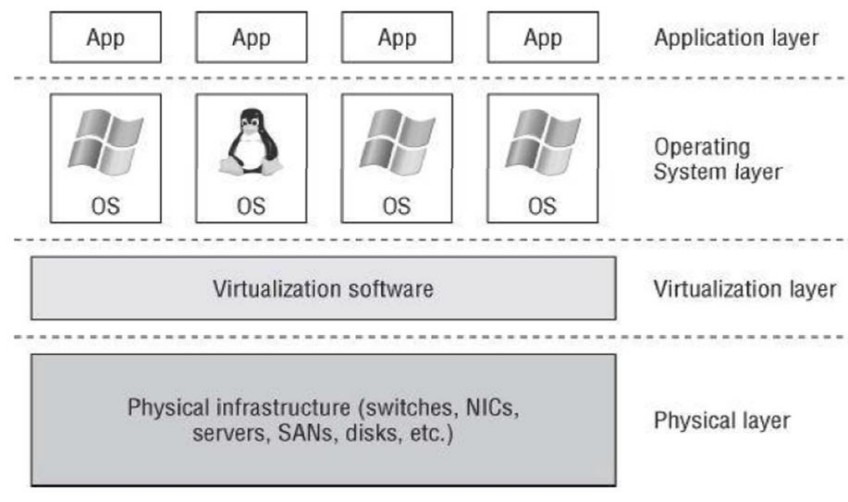
●不同级别的高可用举例;
应用程序级别的高可用性。例如:Oracle Real Application Clusters(oracle RAC);物理硬件的高可用— ESXi主机的网卡多路径冗余,存储的链路多路径冗余(HBA卡冗余),网络交换机和光纤交换机的冗余,存储设备的双控制器冗余,以及服务器,存储等设备的双电源冗余.

●vSphere High Availability的监控对象
➢ ESXi 主机故障
●主机监控
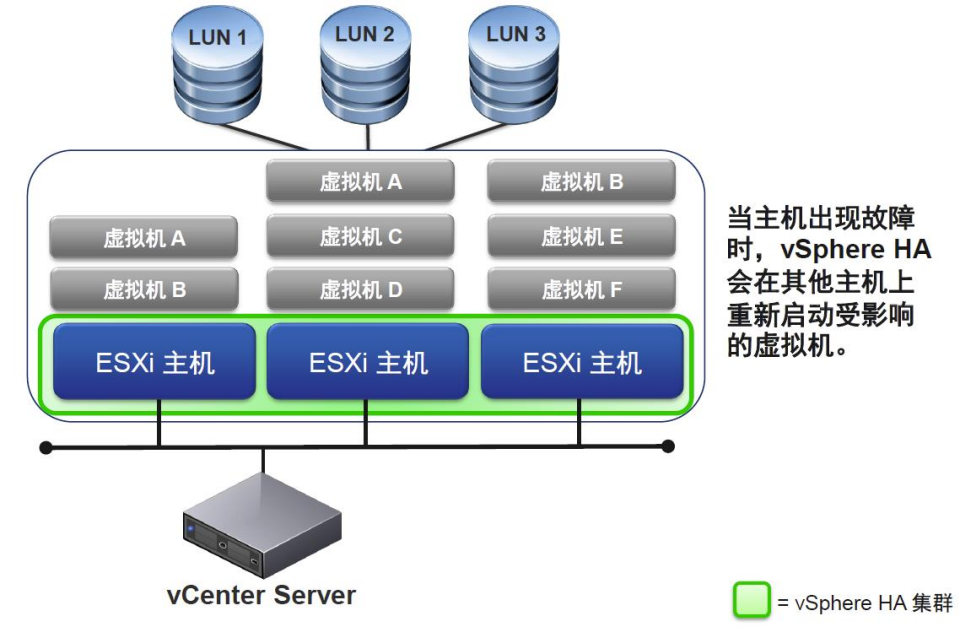
●虚拟机OS监控
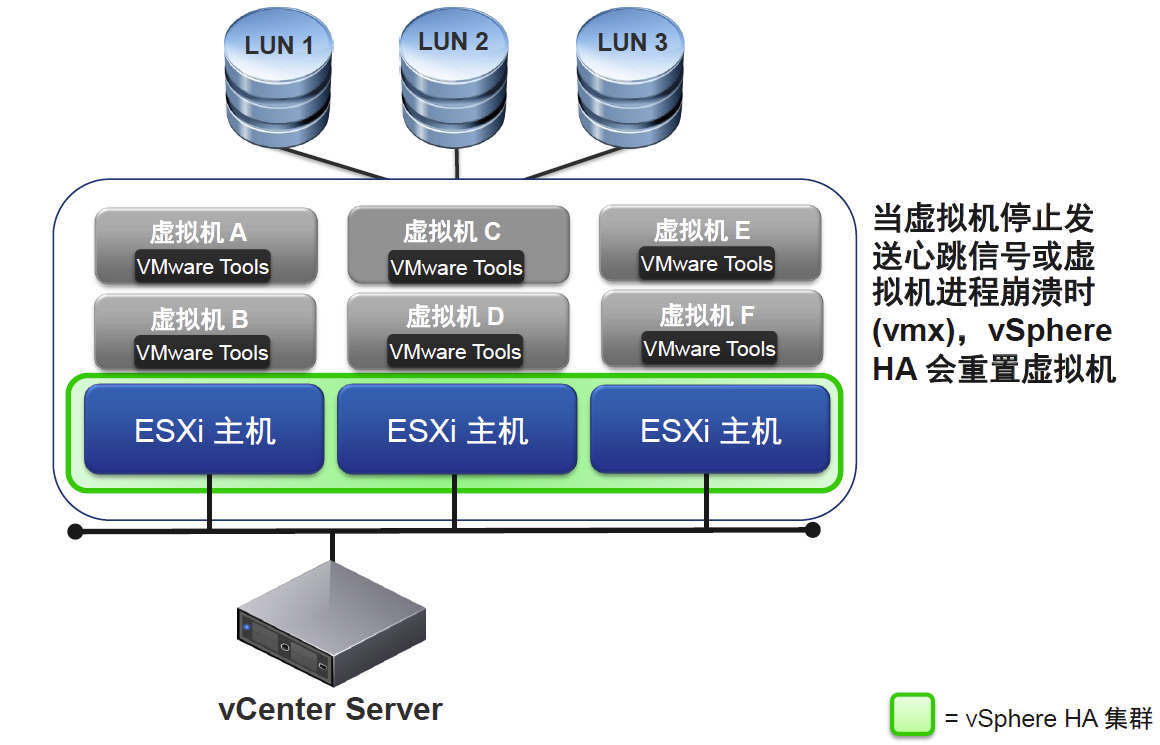
●应用程序监控
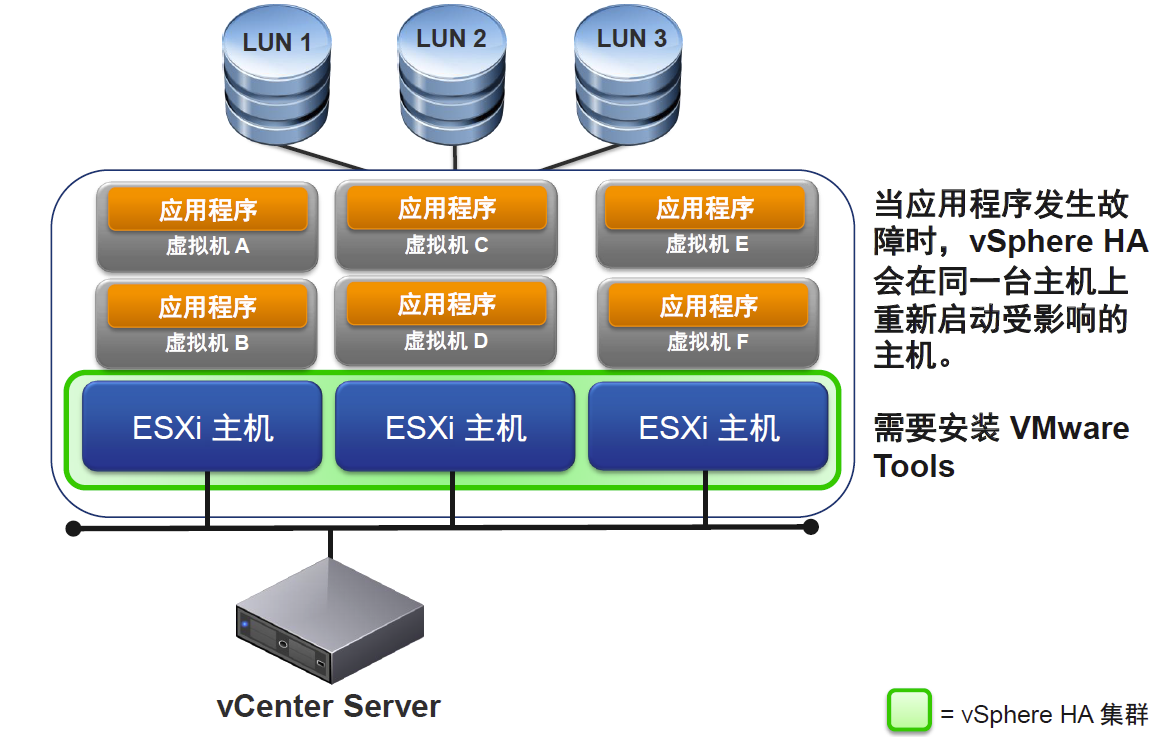
3)vSphere High Availability原理
VMware vSphere High Availability (HA)可为虚拟机中运行的应用提供易于使用、经济高效的高可用性。一旦物理服务器出现故障,VMware HA可在具有备用容量的其他生产服务器中自动重新启动受影响的虚拟机。若操作系统出现故障,vSphere HA会在同一台物理服务器上重新启动受影响的虚拟机。
●Master的作用
Master监控slave主机,当slave主机出现故障时重启虚拟机
●Slave的作用
Slave主机监视本地运行的虚拟机状态,把这些虚拟机运行状态的显著变化发送给Master
●代理通信
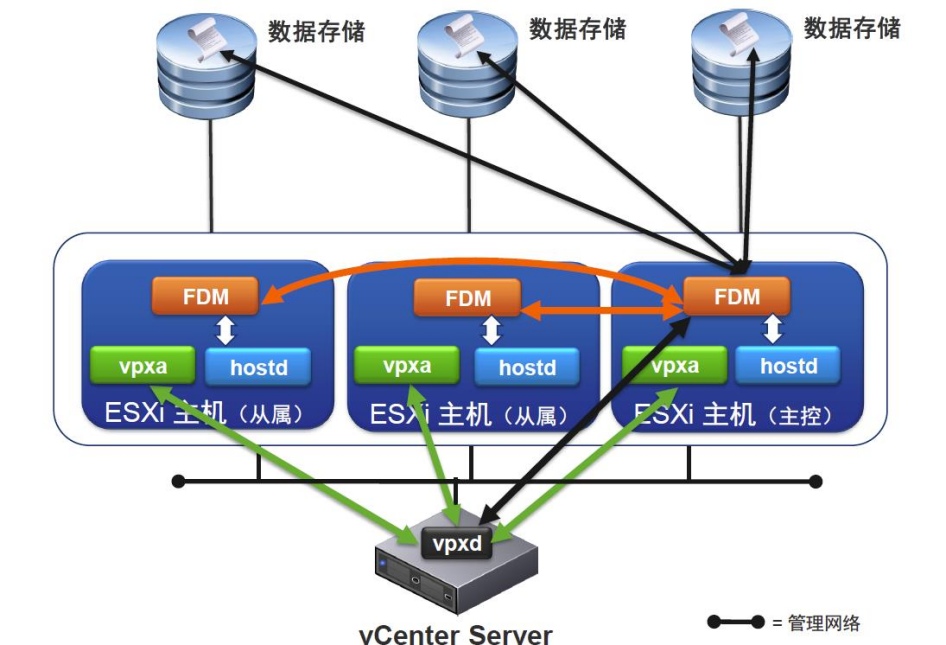
●网络心跳信号

●数据存储心跳信号
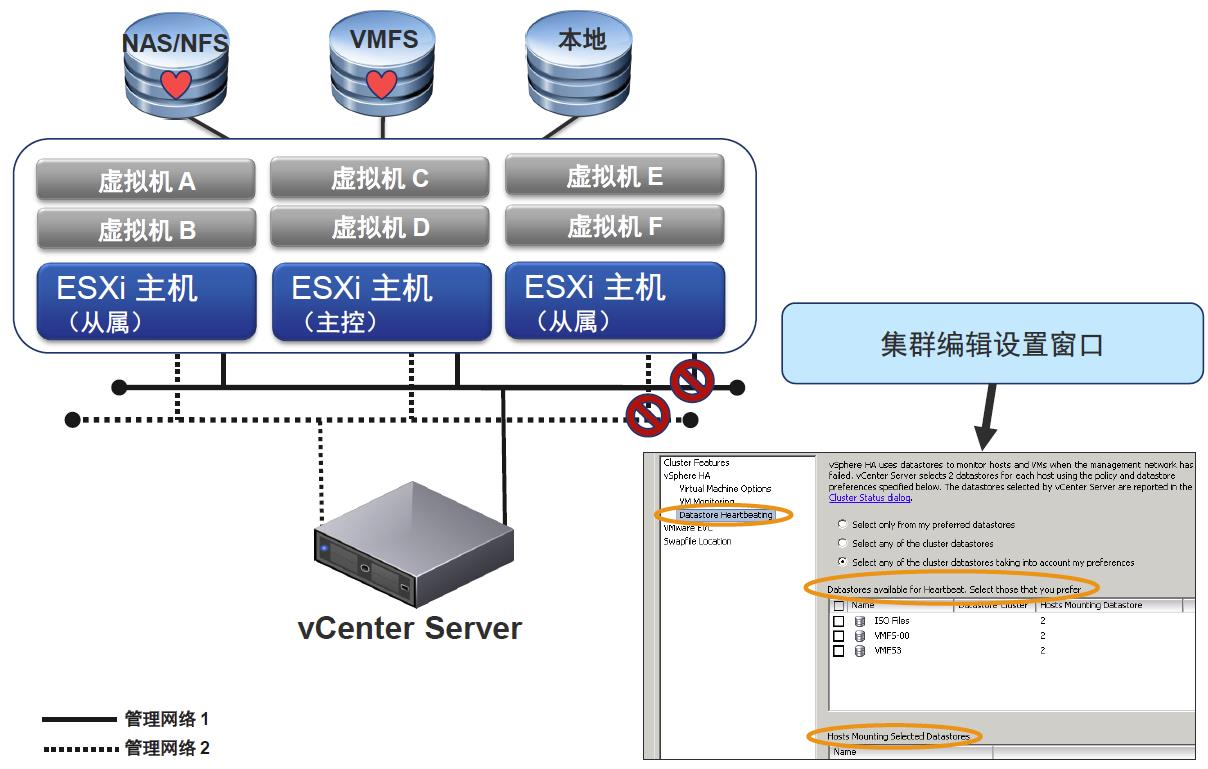
●主机故障分类
vSphere HA 群集的首选主机负责检测从属主机的故障。根据检测到的故障类型,在主机上运行的虚拟机可能需要进行故障切换。首选主机通信通过每秒交换一次网络检测信号来完成群集中从属主机的活跃度监控。当首选主机停止从从属主机接收这些检测信号时,它会在声明该主机已出现故障之前检查主机活跃度。首选主机执行的活跃度检查是要确定从属主机是否在与数据存储心跳之一交换检测信号。而且,首选主机还检查主机是否对发送至其管理 IP 地址的 ICMP ping 进行响应在 vSphere HA 群集中,检测三种类型的主机故障:
●Slave主机故障
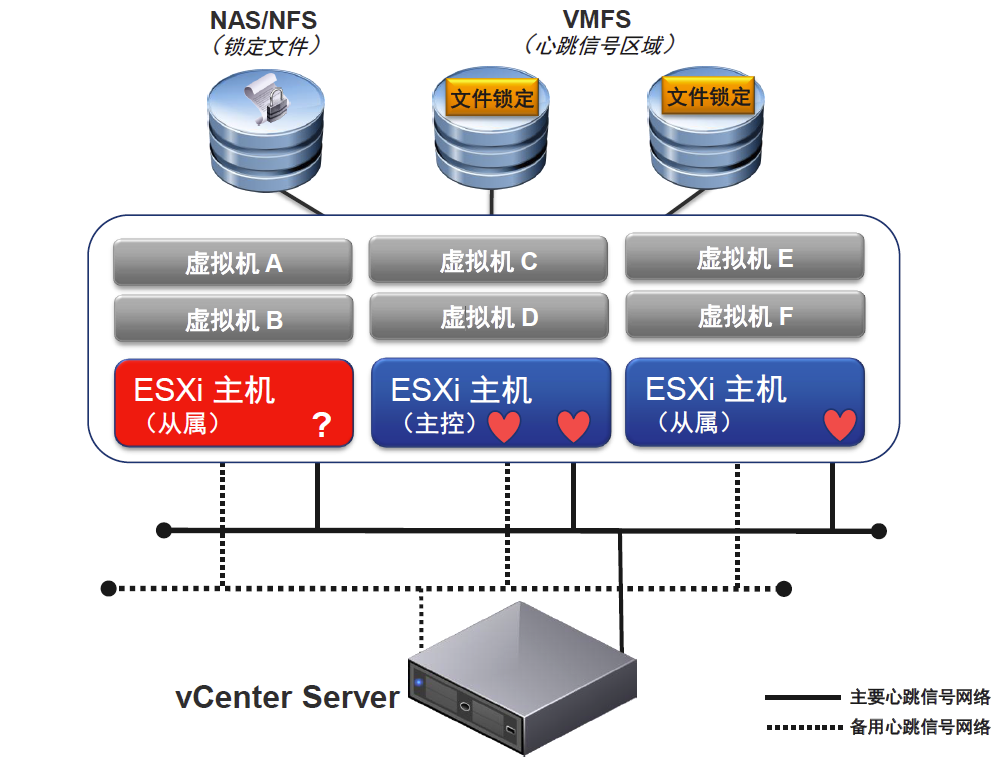
●Master主机故障
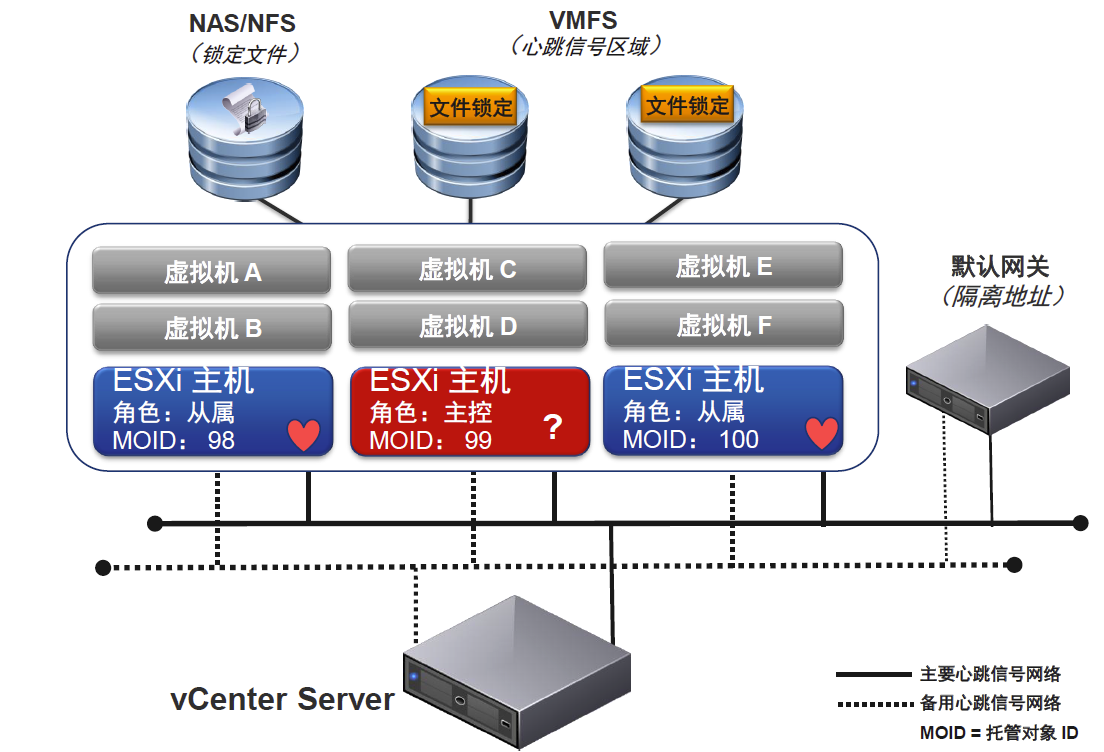
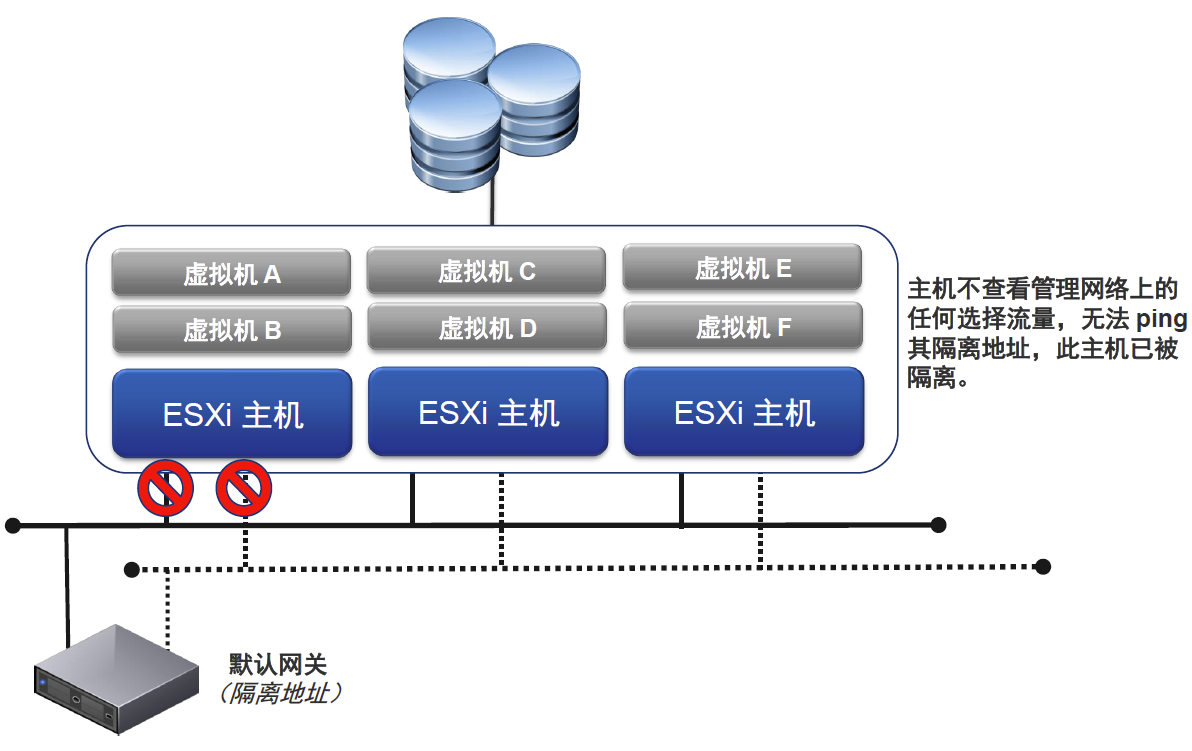
●网络隔离
当一个slave已经检测到自己是网络隔离状态,它会生成一个特殊二进制文件host-X-poweron文件。在heartbeat datastores上.master看到这个标志,它就知道了slave已经是isolation状态。然后master通过vSphere HA锁定其他文件(datastores上的其他文件).当slave主机看到这些文件已经被锁定并确认后.才可以执行配置过的隔离响应动作.(如关机或者关闭电源,或者保持电源打开不变)

微信公众号

新浪微博







